

3DPeS
Overview
3DPeS (3D People Surveillance Dataset) is a surveillance dataset, designed mainly for people re-identification in multi camera systems with non-overlapped field of views, but also applicable to many other tasks, such as people detection, tracking, action analysis and trajectory analysis.
Differently from other re-identification datasets here data for the complete processing chain are available: the camera setting and the 3D environment reconstruction, the hundreds of recorded videos, the camera calibration parameters, the identity of the hundreds of people, detected more than one time by different point of view.
Briefly, the main characteristics of this dataset are:
It contains numerous video sequences taken from a real surveillance setup, composed by 8 different surveillance cameras, monitoring a section of the campus of the University of Modena and Reggio Emilia.
Data were collected over the course of several days.
Subjects were notified of the presence of cameras, but were not coached or instructed in any way.
The illumination between cameras do not vary much, but peoples were recorded multiple times during the course of the day, in clear light and in shadowy areas, resulting in strong variation of light condition in some cases.
The quality of the camera hardware is in line with current standards in visual surveillance, all cameras were from the same vendor and are partially calibrated (position, orientation, pixel aspect ratio and focal length are provided for each one of them).
The quality of the images is mostly constant, uncompressed images with a resolution of 704x576 pixels.
Depending on the cameras position and orientation, peoples were recorded at different zoom levels.
News
- 23 May 2012: Added a selection of snapshots of people from the dataset for Re-Identification and/or Orientation estimation 3DPeS_ReId_Snap.zip See below for details.
- 20 January 2012: Added snapshots file, updated the DB file, added a script mySQL version of the db.
- 04 January 2012: Updated some files. I found some minor bugs (missing images etc.) in some of the archives: the updated files are Set_3, Set_5, Set_6 and backgrounds. I also added some additional information in the Access DB file (specifically the bounding box of the target person and the frame number of the first usefull frame of each video sequence).
- 22 November 2011: Final version of the core dataset available! In the near future I will release an additional small dataset containing only selected snapshots for each person in the full dataset.
- 15 November 2011: Second (draft) version of the dataset released! Almost complete :)
- 25 July 2011: First (draft) version of the dataset released!
The Dataset
A selection of snapshots of people from the dataset, for Re-Identification and/or Orientation estimation: 1012 snapshot of 200 persons.
The .zip file contains:
RGB and MASK folders: RGB folder contains appearance images, MASK folder contains silhouette masks.
THE MASKS WERE EXTRACTED AUTOMATICALLY, they probably contains numerous errors
A text file, 3dpes_train.al (see included file readme_1st.txt for details on the file structure), which contains the following ground truth data:
- Bounding box of the person
- Orientation class (see included image Classi.jpg)
RGB and MASK image files are named following this protocol:
personid_uselessid_FRAME_framenumber_RGB(or MASK).bmp
e.g. 100_3_FRAME_26_RGB.bmp means person_id = 100.
Same number = same person. Different number = different person :-).
All video sequences: you can use this for Re-Identification too.
Videos are NOT synchronized and there is no time travel data for people moving from one camera to the other.
All parts are organized in folders following this structure:
person ID -> Camera ID -> Video Sequence ID
- Download Part 1 - videos of people seen from 3 different cameras
- Download Part 2 - Contains videos of people seen from 1 camera multiple times during working days
- Download Part 3 - Contains videos of people seen from 2 different cameras
- Download Part 4 - Contains videos of people seen from 2 different cameras
- Download Part 5 - Contains videos of people seen from 2 different cameras
- Download Part 6 - Contains videos of people seen from 2 different cameras
Additional Material
- Database File with video informations, camera parameters, target position:
- Background models for all the cameras.
- Snapshot image of each person.
- 3D Model of the Environment
Calibration Data
The calibration data can be found inside this Access file. The ground plane is assumed to be the Z=0 plane. Cameras X and Y position on the ground plane is assumed to be (0.0, 0.0).
Due to the difficult location of the cameras, full calibration was not performed. A simpler calibration method was used: (I. Everts, Nicu Sebe, G. A. Jones. "Cooperative Object Tracking with Multiple PTZ Cameras". In Proceedings of ICIAP'2007. pp.323-330).
All spatial measurements are in millimetres. Frames are provided as JPEG image sequences.
Cameras
| view | Model | Resolution | frame rate |
| 001 | AXIS Q6032-E Network Camera | 704x576 | ~15 |
| 002 | AXIS Q6032-E Network Camera | 704x576 | ~15 |
| 003 | AXIS Q6032-E Network Camera | 704x576 | ~15 |
| 004 | AXIS Q6032-E Network Camera | 704x576 | ~15 |
| 005 | AXIS Q6032-E Network Camera | 704x576 | ~15 |
| 007 | AXIS Q6032-E Network Camera | 704x576 | ~15 |
| 008 | AXIS Q6032-E Network Camera | 704x576 | ~15 |
| 009 | AXIS Q6032-E Network Camera | 704x576 | ~15 |
3D Models
The 3D model of the environment is provided as reference.

It is currently available in Lightwave 3D 10 format and Ogre3D format. See http://www.newtek.com/lightwave/ and http://www.ogre3d.org/ for details on the respective file formats.
WARNING! The model is still a work in progress. To this date not all measures are correct and precise enough for the scientific evaluation of image registration techniques.
Camera layout:
The cameras are installed and cover the locations shown below
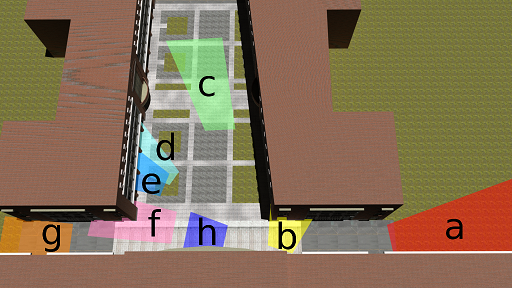
Sample frames:
| view a (camera 004) | view b (camera 002) | view c (camera 003) | view d (camera 007) |
 |
 |
 |
 |
| view e (camera 005) | view f (camera 001) | view g (camera 008) | view h (camera 009) |
 |
 |
 |
 |
Additional Information
If you use this dataset, please cite:
D. Baltieri; R. Vezzani; R. Cucchiara "3DPes: 3D People Dataset for Surveillance and Forensics" Proceedings of the 2011 joint ACM workshop on Human gesture and behavior understanding, vol. 1, Scottsdale, Arizona, USA, pp. 59 -64 , Nov 28 - Dec 1 2011, 2011
If you find any bug or mistakes in the dataset (or if you have any questions) feel free to contact me at davide.baltieri_AT_unimore.it.