

Ludovico Antonio Muratori (LAM) Dataset
S. Cascianelli, V. Pippi, M. Maarand, M. Cornia, L. Baraldi, C. Kermorvant, R. Cucchiara
The Ludovico Antonio Muratori (LAM) dataset is the largest line-level HTR dataset to date and contains 25,823 lines from Italian ancient manuscripts edited by a single author over 60 years. The dataset comes in two configurations: a basic splitting and a date-based splitting which takes into account the age of the author. The first setting is intended to study HTR on ancient documents in Italian, while the second focuses on the ability of HTR systems to recognize text written by the same writer in time periods for which training data are not available.












Please cite with the following BibTeX:
@inproceedings{cascianelli2022lam,
title={The LAM Dataset: A Novel Benchmark for Line-Level Handwritten Text Recognition},
author={Cascianelli, Silvia and Pippi, Vittorio and Martin, Maarand and Cornia, Marcella and Baraldi, Lorenzo and Christopher, Kermorvant and Cucchiara, Rita},
booktitle={International Conference on Pattern Recognition},
year={2022}
}
Dataset info
To make LAM easily accessible to all and to facilitate its use, we present some features that could be useful during the development using this dataset.
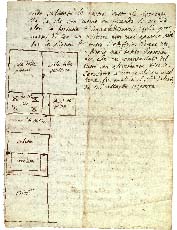
The images below show how the samples are and how the annotations are made.
Samples

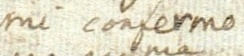
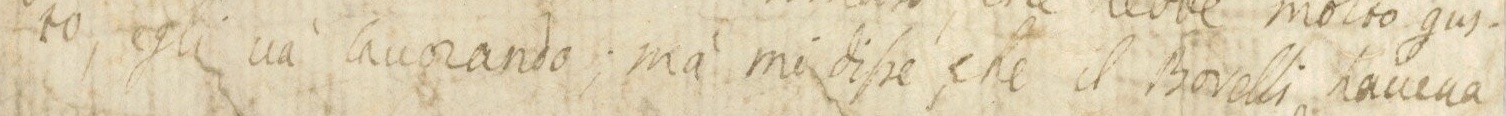
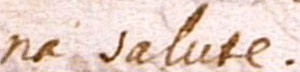


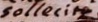

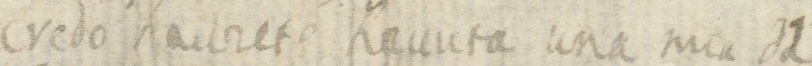
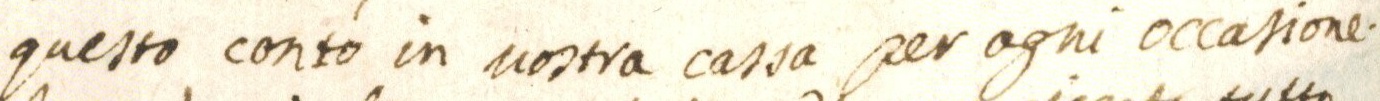
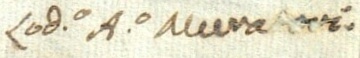
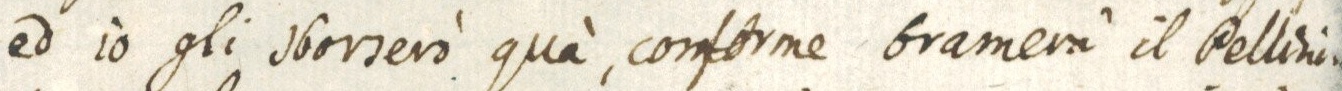
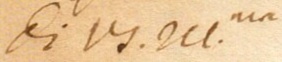
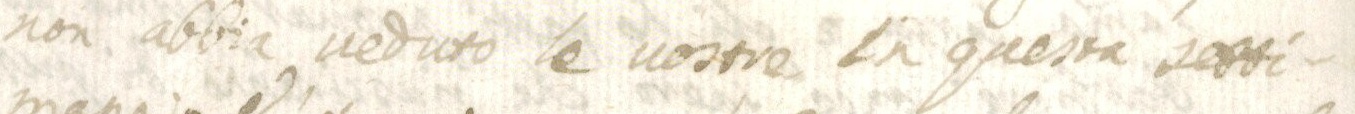
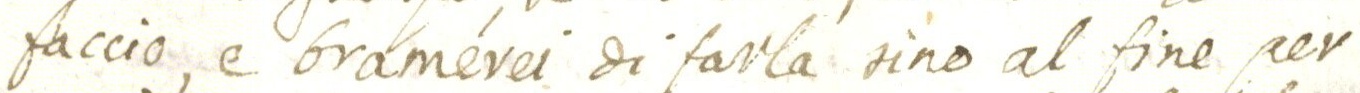
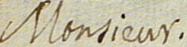
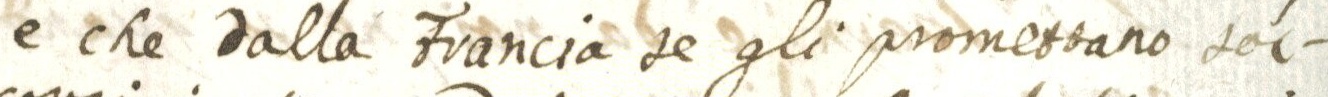
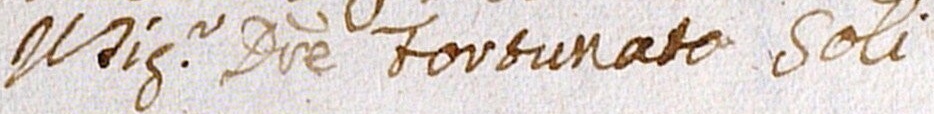
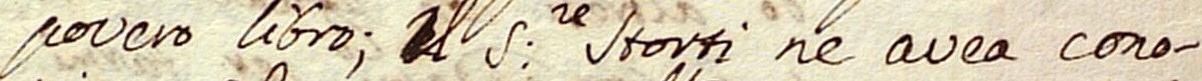
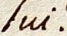
{
"decade_id": ,
"img": ".jpg",
"nameset": "",
"text": "",
"width": ,
"height":
}
Images info
To facilitate the network design process we provide the width and height distribution of all samples in the dataset. Moreover, the following table shows which are the minimum and maximum sizes of all images.
| Min | Max | Avg | |
|---|---|---|---|
| Width | 29 px | 1700 px | 658 px |
| Height | 14 px | 235 px | 53 px |
Dataset comparison
Designing and developing effective HTR solutions requires the availability of large data collections, which should capture both the visual variability of the task and represent different languages. In the following, we compare LAM with other line-level datasets of western-characters, since these are more closely related to our proposed dataset.
Text info
LAM contains a label length distribution very similar to IAM. The graphs show that there isn't an evident difference between the different sets of distributions.
| Min | Max | Avg |
|---|
Decade info
The dataset is divided into 6 decades distributed along with the Ludovico Antonio Muratori's life. Each sample has the field decade_id that indicates the decade index in the following table:
| Index | Date range | Samples |
|---|
Splits
| Split | Train | Validation | Test | Total |
|---|---|---|---|---|
| Basic | 19830 (77%) | 2470 (10%) | 3523 (13%) | 25823 |
| Leave decade 1 out | 17205 (68%) | 1911 (8%) | 6067 (24%) | 25183 |
| Leave decade 2 out | 17205 (77%) | 1911 (9%) | 3276 (15%) | 22392 |
| Leave decade 3 out | 17205 (82%) | 1911 (9%) | 1950 (9%) | 21066 |
| Leave decade 4 out | 17205 (68%) | 1911 (8%) | 6042 (24%) | 25158 |
| Leave decade 5 out | 17205 (75%) | 1911 (8%) | 3858 (17%) | 22974 |
| Leave decade 6 out | 17205 (74%) | 1911 (8%) | 3990 (17%) | 23106 |