

SimBa Dataset
A. Simoni, S. Pini, G. Borghi, R. Vezzani
SimBa is a collection of synthetic and real data for the robot pose estimation task in collaborative environments. Among several collaborative robots, we chose the Rethink Baxter, which moves respectively to a set of random pick-n-place locations on a table, assuming realistic poses. The dataset contains RGB-D images with annotations for the 3D joints and the pick-n-place locations. The synthetic part contains over 350k annotated RGB-D images, while the real part contains over 20k annotated RGB-D frames.
Please cite with the following BibTeX:
@article{simoni2022semi,
title={Semi-Perspective Decoupled Heatmaps for 3D Robot Pose Estimation from Depth Maps},
author={Simoni, Alessandro and Pini, Stefano and Borghi, Guido and Vezzani, Roberto},
journal={IEEE Robotics and Automation Letters},
year={2022},
publisher={IEEE}
}
Download
Please follow the instructions in the README file to build the dataset correctly.
In the following, you can download each part of the dataset separately depending on your research
interests:
Dataset info
In the following, further details about the acquisition process, the image data, the annotations and the dataset splits are reported below. Each section describes separately synthetic and real data.
Data acquisition (powered by

)

Synthetic
We collected data using ROS and Gazebo for simulating a synthetic environment in which the robot performs random pick-n-place motions. We record 2 runs with different initialization seeds. Each run contains 20 recording sequences composed of 10 pick-n-place motions split equally between left and right robot arm. Each sequence is recorded by 3 anchor cameras (center, left, right) which are randomly moved within a sphere of 1m diameter.

Real
We collected data using ROS and a time-of-flight Microsoft Kinect One (second version) sensor capturing the moving robot from 3 camera positions (center, left, right). We record 20 pick-n-place sequences from each camera location and split them equally between right and left arm.
Images
Synthetic
The synthetic part contains 10FPS videos with RGB (1980x1080) and depth (512x424) frames. In total there are 40 sequences with over 350k annotated frames.

Real
The real part contains 15FPS videos with RGB (1980x1080) and depth (512x424) frames. In total there are 20 sequences with over 20k annotated frames.

Annotations
Synthetic
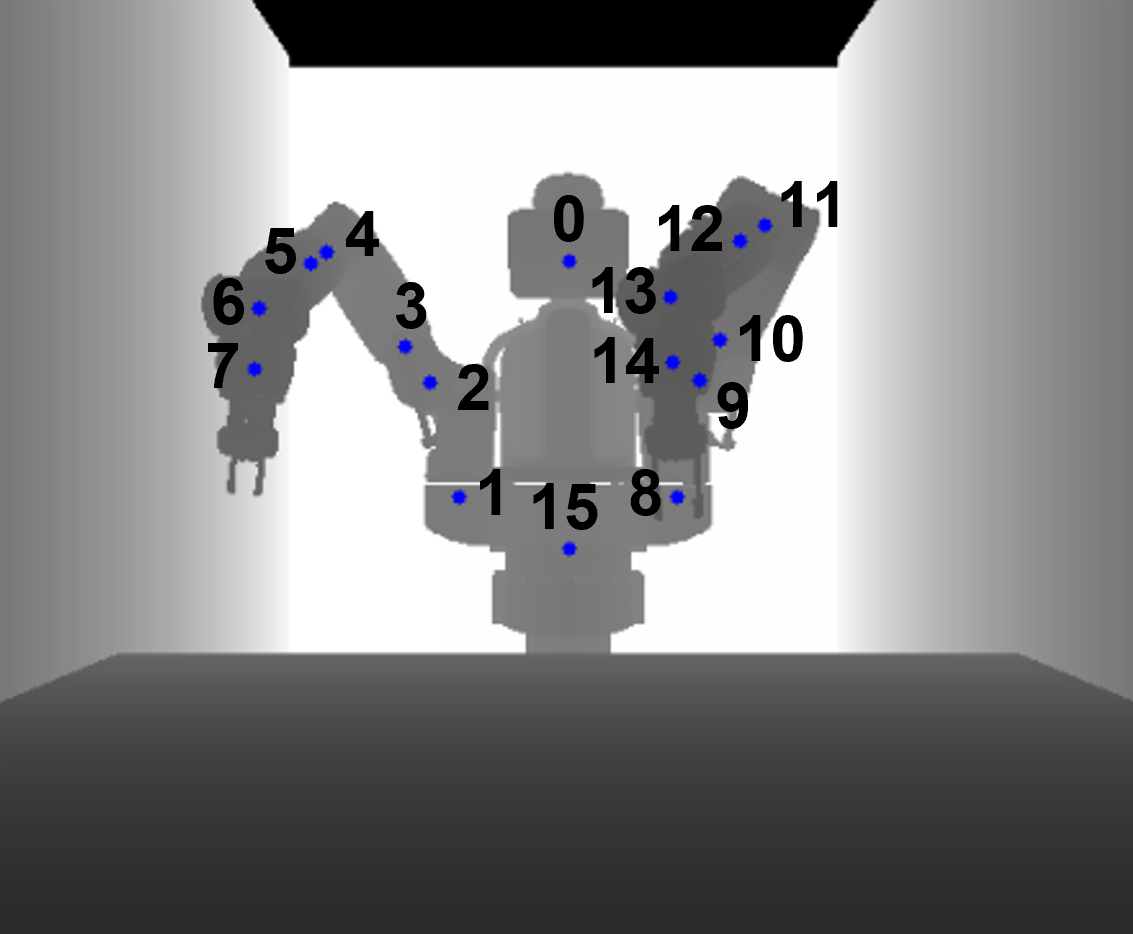
0: "head", 8: "left upper shoulder", 1: "right upper shoulder", 9: "left lower shoulder", 2: "right lower shoulder", 10: "left upper elbow", 3: "right upper elbow", 11: "left lower elbow", 4: "right lower elbow", 12: "left upper forearm", 5: "right upper forearm", 13: "left lower forearm", 6: "right lower forearm", 14: "left wrist", 7: "right wrist", 15: "base"
The synthetic annotations contain information about the 3D robot joints positions, the pick-n-place locations and the camera positions. They are stored in JSON files with the structure described below:
Real
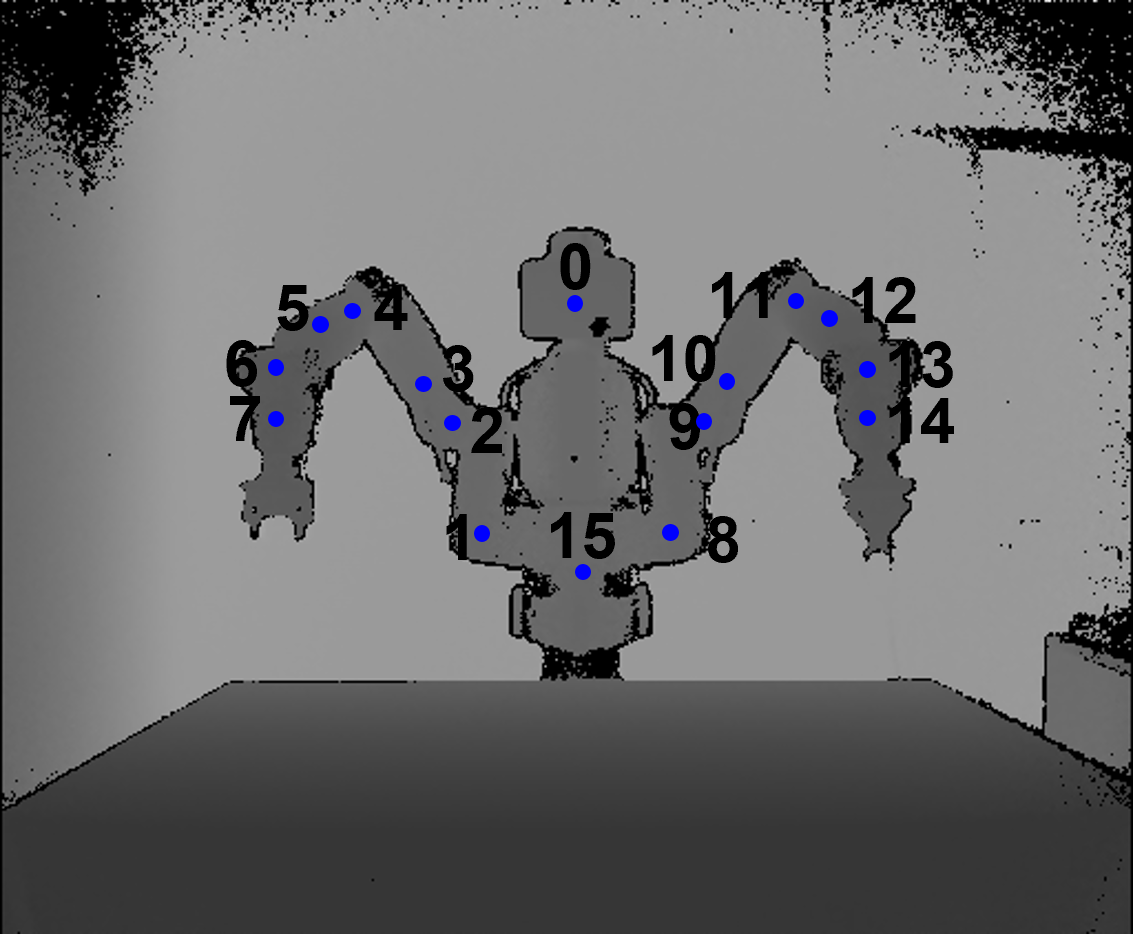
0: "head", 8: "left upper shoulder", 1: "right upper shoulder", 9: "left lower shoulder", 2: "right lower shoulder", 10: "left upper elbow", 3: "right upper elbow", 11: "left lower elbow", 4: "right lower elbow", 12: "left upper forearm", 5: "right upper forearm", 13: "left lower forearm", 6: "right lower forearm", 14: "left wrist", 7: "right wrist", 15: "base"
The real annotations contain information about the 3D robot joints positions and camera positions. The joints are saved as TXT files (one file per joint) while the camera info in a JSON file with the structure described below:
Splits
Synthetic
The synthetic data are split into 28 train sequences, 4 validation sequences and 8 test sequences. Each sequences is sampled every 10 frames.
| Train | Validation | Test | Total |
|---|---|---|---|
| 26603 (70%) | 3842 (10%) | 7490 (20%) | 37935 |
Real
The real sequences represent a single test split. Each sequence is sampled every 5 frames obtaining a test of 4032 images.
Contacts
If you have any questions about our dataset, please use the
issues section on the github repo.
Alternatively, send an e-mail at
alessandro.simoni@unimore.it.
Acknowledgment
This work was supported by the
XiLab Unimore that helped us recording the real sequences with the Baxter robot.
We thank also Stan Birchfield and Timothy E. Lee of NVIDIA for the helpful discussions.