

NVIDIA AI Technology Center at Unimore
UNIMORE participates to the NVIDIA AI Nation program, which has been launched in Modena last January, with a local NVIDIA AI Technical Centre, namely NVAITC@Unimore. The goal of the technical centre is to provide support for computationally intensive research activities, which at AImageLab range from video analysis to fully-attentive models and self-supervision. Such research activities are carried on by close cooperation between UNIMORE (and consequently AImagelab) and NVIDIA and have the common need for high performance computing due to their computational requirements: the collaboration opens up the possibility of solving these tasks, also thanks to NVIDIA's expertise in the field.
At present, we have activated two research streams, on human activity recognition and on transformer-based models, with a focus on Novel Object Captioning. In the near future we also plan to open other research streams with intensive computational demands.
Human action recognition.
Deep architectures able to handle video clips gained increasing attention in the last few years, especially for tasks involving human action understanding. Nevertheless, existing models are still far from begin satisfactory, if compared to state-of-the-art deep image-based networks. The third dimension, i.e. the time axis, highly affects models complexity: it's still an open question how to handle the temporal domain and its strong redundancy in order to limit this complexity. In this project we aim to search for alternative solutions in the field of action recognition, thanks to the NVAITC support. The goal is to learn better Spatio-temporal representations which can be easily transferred to a number of more specific tasks involving human behavior understanding (from Spatio-temporal action localization to temporal action detection). We expect these models to require huge computational resources (from I/O to GPUs), and we aim to exploit the capabilities of the new accelerated partition of CINECA (Marconi100).

Transformer-based models.
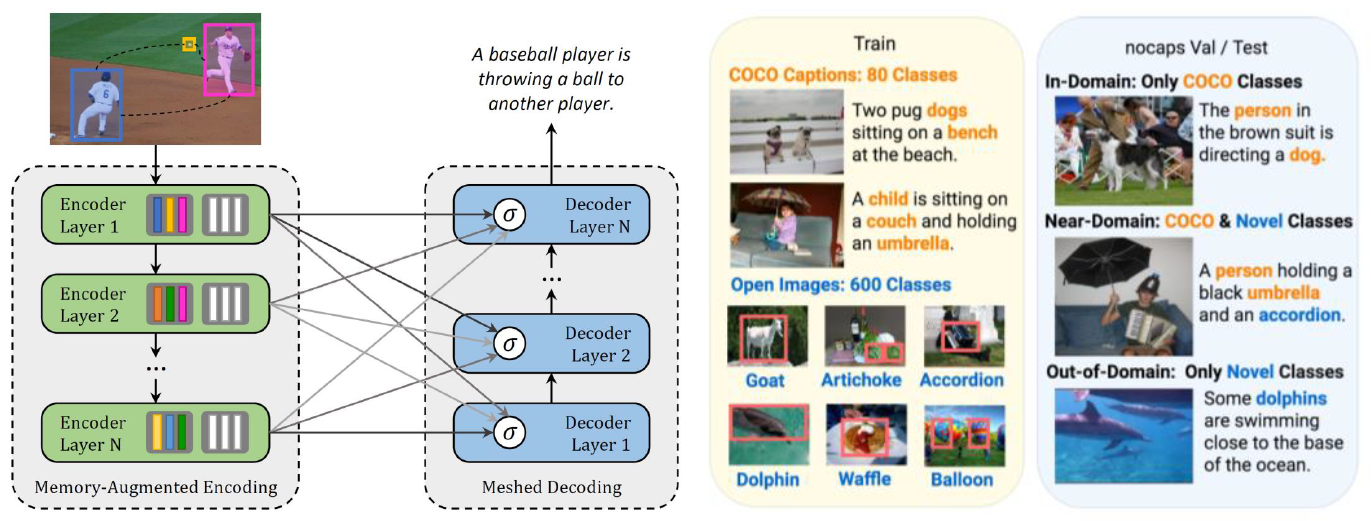
Image Captioning is the task of producing natural language sentences to describe the visual content of an image. One of the most critical limitations of these models is that they are built on a number of image-caption pairs which contain only a shallow view of in-domain objects. Novel Object Captioning (NOC) goes a step further from this by trying to generalize the model in real-word scenarios to describe novel objects, unseen during the training phase. Indeed, in this task, test images contain previously unobserved, 'novel' objects that are drawn from a target distribution that differs from the source/training distribution. These tasks have usually been tackled via Recurrent Neural Network (RNNs) in most literature, but the recent advent of fully-attentive models has led the research to new opportunities in terms of performances and representation capabilities, as testified by the Transformer and BERT architectures. Therefore in this project we will investigate the influence of the attentive paradigm, along with other emerging ones such as self-supervision, to enhance models effectiveness when describing unseen objects.
Publications
| 1 | Tomei, Matteo; Baraldi, Lorenzo; Calderara, Simone; Bronzin, Simone; Cucchiara, Rita "RMS-Net: Regression and Masking for Soccer Event Spotting" Proceedings of the 25th International Conference on Pattern Recognition, Milan, Italy, pp. 7699 -7706 , 10-15 January 2021, 2021 | DOI: 10.1109/ICPR48806.2021.9412268 Conference |
| 2 |
Tomei, Matteo; Baraldi, Lorenzo; Calderara, Simone; Bronzin, Simone; Cucchiara, Rita
"Video action detection by learning graph-based spatio-temporal interactions"
COMPUTER VISION AND IMAGE UNDERSTANDING,
vol. 206,
pp. 1
-9
,
2021
| DOI: 10.1016/j.cviu.2021.103187
Journal

|
| 3 |
Cornia, Marcella; Baraldi, Lorenzo; Cucchiara, Rita
"SMArT: Training Shallow Memory-aware Transformers for Robotic Explainability"
International Conference on Robotics and Automation,
Paris, France,
pp. 1128
-1134
,
May, 31 - June, 4,
2020
| DOI: 10.1109/ICRA40945.2020.9196653
Conference
|
| 4 |
Cornia, Marcella; Stefanini, Matteo; Baraldi, Lorenzo; Cucchiara, Rita
"Meshed-Memory Transformer for Image Captioning"
2020 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR 2020),
Seattle, WA, USA,
pp. 10575
-10584
,
June 14-19 2020,
2020
| DOI: 10.1109/CVPR42600.2020.01059
Conference
|
Project Info
