

Research on Vision and Language
Transformer-based Image Captioning
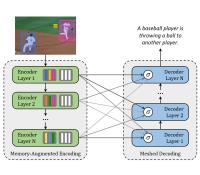
Image captioning is the task of describing the visual content of an image in natural language. As such, it requires an algorithm to understand and model the relationships between visual and textual elements, and to generate a sequence of output words. This has usually been tackled via Recurrent Neural Network models, in which the sequential nature of language is modeled with the recurrent relations of either RNNs or LSTMs. This schema has remained the dominant approach in the last few years, with the exception of the investigation of Convolutional language models, which however did not become a leading choice. The recent advent of fully-attentive models, in which the recurrent relation is abandoned in favour of the use of self-attention, offers unique opportunities in terms of set and sequence modeling performances. Also, this setting offers novel architectural modeling capabilities, as for the first time the attention operator is used in a multi-layer and extensible fashion. Nevertheless, the multi-modal nature of image captioning demands for specific architectures, different from those employed for the understanding of a single modality. Following this premise, we investigate the design of novel fully-attentive architectures for image captioning.
Controllable Captioning
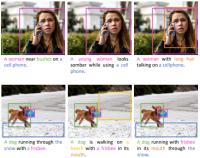
Current captioning approaches can describe images using black-box architectures whose behavior is hardly controllable and explainable from the exterior. As an image can be described in infinite ways depending on the goal and the context at hand, a higher degree of controllability is needed to apply captioning algorithms in complex scenarios. To address these issues, we have introduced a novel framework for image captioning which can generate diverse descriptions by allowing both grounding and controllability. Given a control signal in the form of a sequence or set of image regions, we generate the corresponding caption through a recurrent architecture which predicts textual chunks explicitly grounded on regions, following the constraints of the given control.
From Show to Tell: A Survey on Image Captioning

Connecting Vision and Language plays an essential role in Generative Intelligence. For this reason, in the last few years, a large research effort has been devoted to image captioning, i.e. the task of describing images with syntactically and semantically meaningful sentences. Starting from 2015, the task has been addressed with pipelines generally composed of a visual encoding step and a language model for text generation. During these years, we have witnessed a great evolution in the encoding of visual content through the exploitation of regions, objects attributes and relationships. Similarly, the same evolution has happened in the development of language models and of multi-modal connections, with the introduction of fully-attentive approaches and BERT-like early-fusion strategies.
However, regardless of the impressive results obtained, research in image captioning has not reached a conclusive answer. This work aims at providing a comprehensive overview of image captioning approaches, defining effective taxonomies for encoding and generation, datasets and metrics for this task. We discuss training and pre-training strategies, such as cross-entropy, masked language models, and reinforcement learning, as well as the power of recent additions like self-attention. Moreover, many variants of the problem are analyzed, such as novel object captioning, controllable captioning, unsupervised captioning, and dense captioning. The final goal of this work is to provide a tool to understand the present research and highlight future directions for a fascinating area of research where Computer Vision and Natural Language Processing can find an optimal synergy.