

LAMV: Learning to align and match videos with kernelized temporal layers
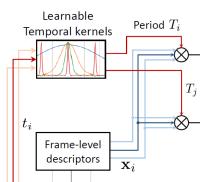
Abstract: This paper considers a learnable approach for comparing and aligning videos. Our architecture builds upon and revisits temporal match kernels within neural networks: we propose a new temporal layer that finds temporal alignments by maximizing the scores between two sequences of vectors, according to a time-sensitive similarity metric parametrized in the Fourier domain. We learn this layer with a temporal proposal strategy, in which we minimize a triplet loss that takes into account both the localization accuracy and the recognition rate. We evaluate our approach on video alignment, copy detection and event retrieval. Our approach outperforms the state on the art on temporal video alignment and video copy detection datasets in comparable setups. It also attains the best reported results for particular event search, while precisely aligning videos.
Citation:
Baraldi, Lorenzo; Douze, Matthijs; Cucchiara, Rita; Jégou, Hervé "LAMV: Learning to align and match videos with kernelized temporal layers" 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, USA, pp. 7804 -7813 , June 18-22, 2018 DOI: 10.1109/CVPR.2018.00814
not available
Paper download:
- Author version:
- DOI: 10.1109/CVPR.2018.00814