

Back to the research area
We evaluate our approach on three large-scale datasets: the Montreal Video Annotation dataset, the MPII Movie Description dataset and the Microsoft Video Description Corpus. Experiments show that our approach can discover appropriate hierarchical representations of input videos and improve the state of the art results on movie description datasets.

Video Captioning
Automatically describing a video in natural language is an important challenge for computer vision and machine learning. This task, called video captioning, is a crucial achievement towards machine intelligence and also the support of a number of potential applications. Indeed, bringing together vision and language, video captioning can be leveraged for video retrieval, to enhance content search on video sharing and streaming platforms, as well as to generate automatic subtitles and to help visually impaired people to get an insight of the content of a video
Abstract
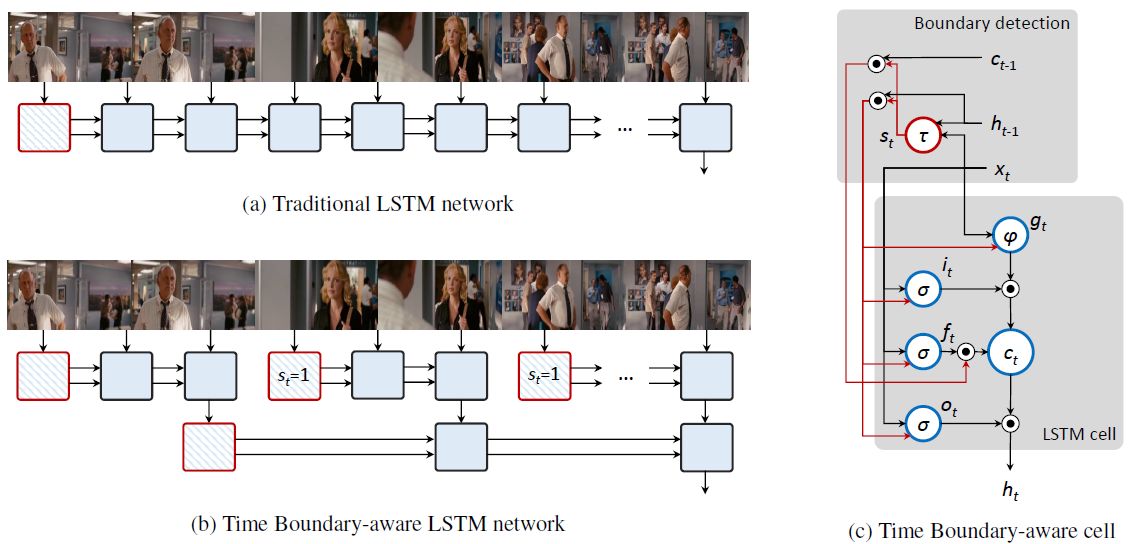
The use of Recurrent Neural Networks for video captioning has recently gained a lot of attention, since they can be used both to encode the input video and to generate the corresponding description. We recently developed a recurrent video encoding scheme which can discover and leverage the hierarchical structure of the video. Unlike the classical encoder-decoder approach, in which a video is encoded continuously by a recurrent layer, we propose a novel LSTM cell, which can identify discontinuity points between frames or segments and modify the temporal connections of the encoding layer accordingly.We evaluate our approach on three large-scale datasets: the Montreal Video Annotation dataset, the MPII Movie Description dataset and the Microsoft Video Description Corpus. Experiments show that our approach can discover appropriate hierarchical representations of input videos and improve the state of the art results on movie description datasets.
Video
Paper
Hierarchical Boundary-Aware Neural Encoder for Video Captioning
L. Baraldi, C. Grana, R.Cucchiara
CVPR 2017
Reference
If you find this useful in your work, please consider citing:
@inproceedings{baraldi17cvpr,
title = {Hierarchical Boundary-Aware Neural Encoder for Video Captioning},
author = {Baraldi, Lorenzo and Grana, Costantino and Cucchiara, Rita},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Publications
| 1 |
Cornia, Marcella; Baraldi, Lorenzo; Serra, Giuseppe; Cucchiara, Rita
"Visual Saliency for Image Captioning in New Multimedia Services"
Multimedia & Expo Workshops (ICMEW), 2017 IEEE International Conference on,
Hong Kong,
pp. 309
-314
,
July 10-14, 2017,
2017
| DOI: 10.1109/ICMEW.2017.8026277
Conference

|
| 2 |
Baraldi, Lorenzo; Grana, Costantino; Cucchiara, Rita
"Hierarchical Boundary-Aware Neural Encoder for Video Captioning"
Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on,
vol. 2017-,
Honolulu, Hawaii,
pp. 3185
-3194
,
July, 22-25,
2017
| DOI: 10.1109/CVPR.2017.339
Conference
|
