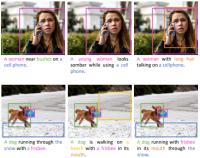
Controllable Captioning
Current captioning approaches can describe images using black-box architectures whose behavior is hardly controllable and explainable from the exterior. As an image can be described in infinite ways depending on the goal and the context at hand, a higher degree of controllability is needed to apply captioning algorithms in complex scenarios. To address these issues, we have introduced a novel framework for image captioning which can generate diverse descriptions by allowing both grounding and controllability. Given a control signal in the form of a sequence or set of image regions, we generate the corresponding caption through a recurrent architecture which predicts textual chunks explicitly grounded on regions, following the constraints of the given control.
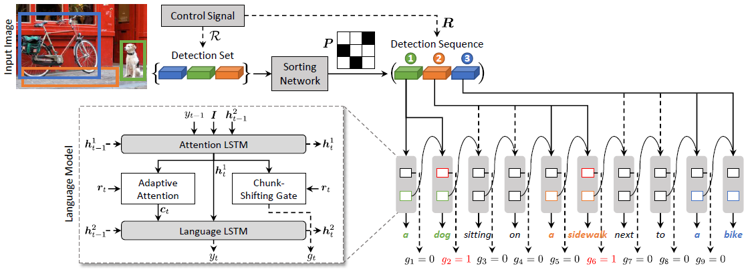


Show, Control and Tell: A Framework for Generating Controllable and Grounded Captions
M.Cornia, L.Baraldi, R.Cucchiara
CVPR 2019
Download PDFSource Code
Publications
| 1 |
Cornia, Marcella; Baraldi, Lorenzo; Cucchiara, Rita
"Show, Control and Tell: A Framework for Generating Controllable and Grounded Captions"
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition,
vol. 2019-,
Long Beach, CA, USA,
pp. 8299
-8308
,
June 16-20 2019,
2019
| DOI: 10.1109/CVPR.2019.00850
Conference

|