Transformer-based Image Captioning
Image captioning is the task of describing the visual content of an image in natural language. As such, it requires an algorithm to understand and model the relationships between visual and textual elements, and to generate a sequence of output words. This has usually been tackled via Recurrent Neural Network models, in which the sequential nature of language is modeled with the recurrent relations of either RNNs or LSTMs. This schema has remained the dominant approach in the last few years, with the exception of the investigation of Convolutional language models, which however did not become a leading choice. The recent advent of fully-attentive models, in which the recurrent relation is abandoned in favour of the use of self-attention, offers unique opportunities in terms of set and sequence modeling performances. Also, this setting offers novel architectural modeling capabilities, as for the first time the attention operator is used in a multi-layer and extensible fashion. Nevertheless, the multi-modal nature of image captioning demands for specific architectures, different from those employed for the understanding of a single modality. Following this premise, we investigate the design of novel fully-attentive architectures for image captioning.
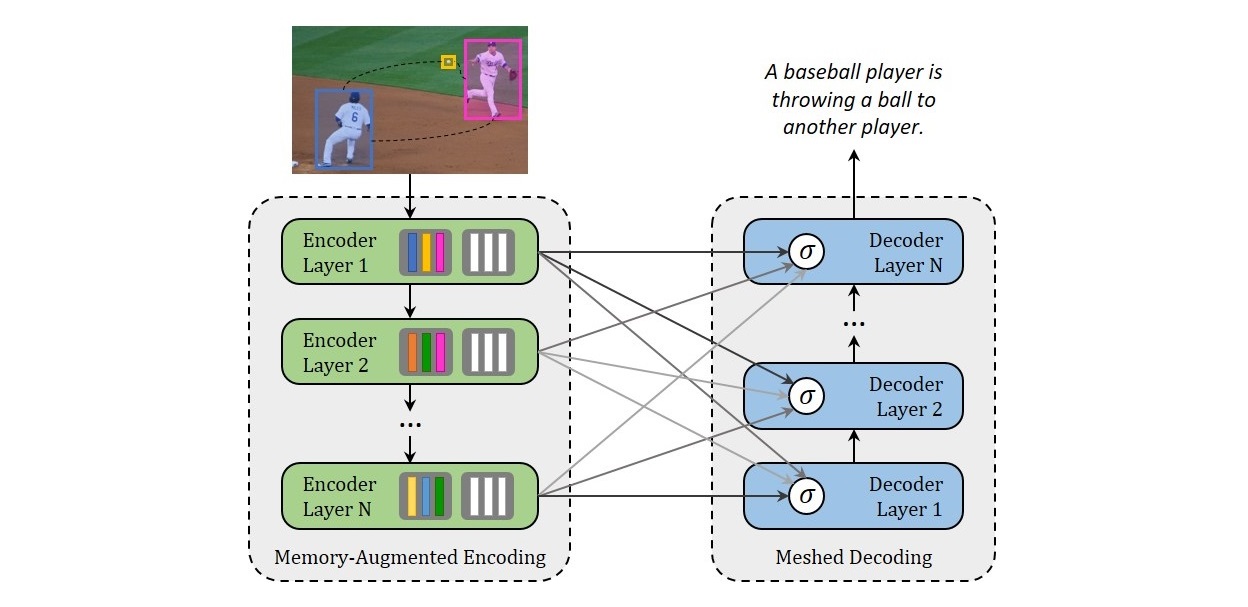
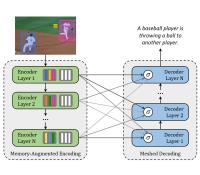
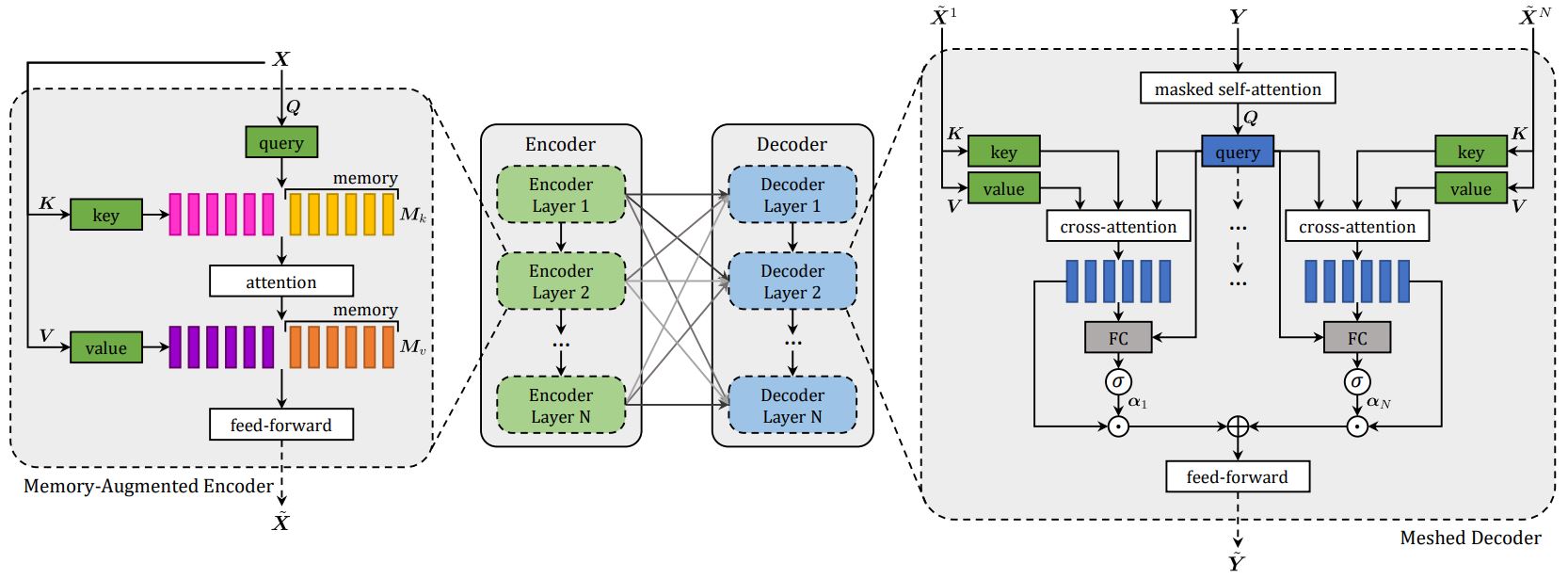
Meshed-Memory Transformer for Image Captioning
Transformer-based architectures represent the state of the art in sequence modeling tasks like machine translation and language understanding. Their applicability to multi-modal contexts like image captioning, however, is still largely under-explored. With the aim of filling this gap, we present M� - a Meshed Transformer with Memory for Image Captioning. The architecture improves both the image encoding and the language generation steps: it learns a multi-level representation of the relationships between image regions integrating learned a priori knowledge, and uses a mesh-like connectivity at decoding stage to exploit low- and high-level features. Experimentally, we investigate the performance of the we present M� Transformer and different fully-attentive models in comparison with recurrent ones. When tested on COCO, our proposal achieves a new state of the art in single-model and ensemble configurations on the "Karpathy" test split and on the online test server. We also assess its performances when describing objects unseen in the training set.
Paper

Meshed-Memory Transformer for Image Captioning
M.Cornia, M. Stefanini, L.Baraldi, R.Cucchiara
CVPR 2020
Download PDFSource Code
Publications
| 1 |
Cornia, Marcella; Baraldi, Lorenzo; Cucchiara, Rita
"SMArT: Training Shallow Memory-aware Transformers for Robotic Explainability"
International Conference on Robotics and Automation,
Paris, France,
pp. 1128
-1134
,
May, 31 - June, 4,
2020
| DOI: 10.1109/ICRA40945.2020.9196653
Conference

|