

From Show to Tell: A Survey on Image Captioning
Connecting Vision and Language plays an essential role in Generative Intelligence. For this reason, in the last few years, a large research effort has been devoted to image captioning, i.e. the task of describing images with syntactically and semantically meaningful sentences. Starting from 2015, the task has been addressed with pipelines generally composed of a visual encoding step and a language model for text generation. During these years, we have witnessed a great evolution in the encoding of visual content through the exploitation of regions, objects attributes and relationships. Similarly, the same evolution has happened in the development of language models and of multi-modal connections, with the introduction of fully-attentive approaches and BERT-like early-fusion strategies.
However, regardless of the impressive results obtained, research in image captioning has not reached a conclusive answer. This work aims at providing a comprehensive overview of image captioning approaches, defining effective taxonomies for encoding and generation, datasets and metrics for this task. We discuss training and pre-training strategies, such as cross-entropy, masked language models, and reinforcement learning, as well as the power of recent additions like self-attention. Moreover, many variants of the problem are analyzed, such as novel object captioning, controllable captioning, unsupervised captioning, and dense captioning. The final goal of this work is to provide a tool to understand the present research and highlight future directions for a fascinating area of research where Computer Vision and Natural Language Processing can find an optimal synergy.
Datasets for Image Captioning

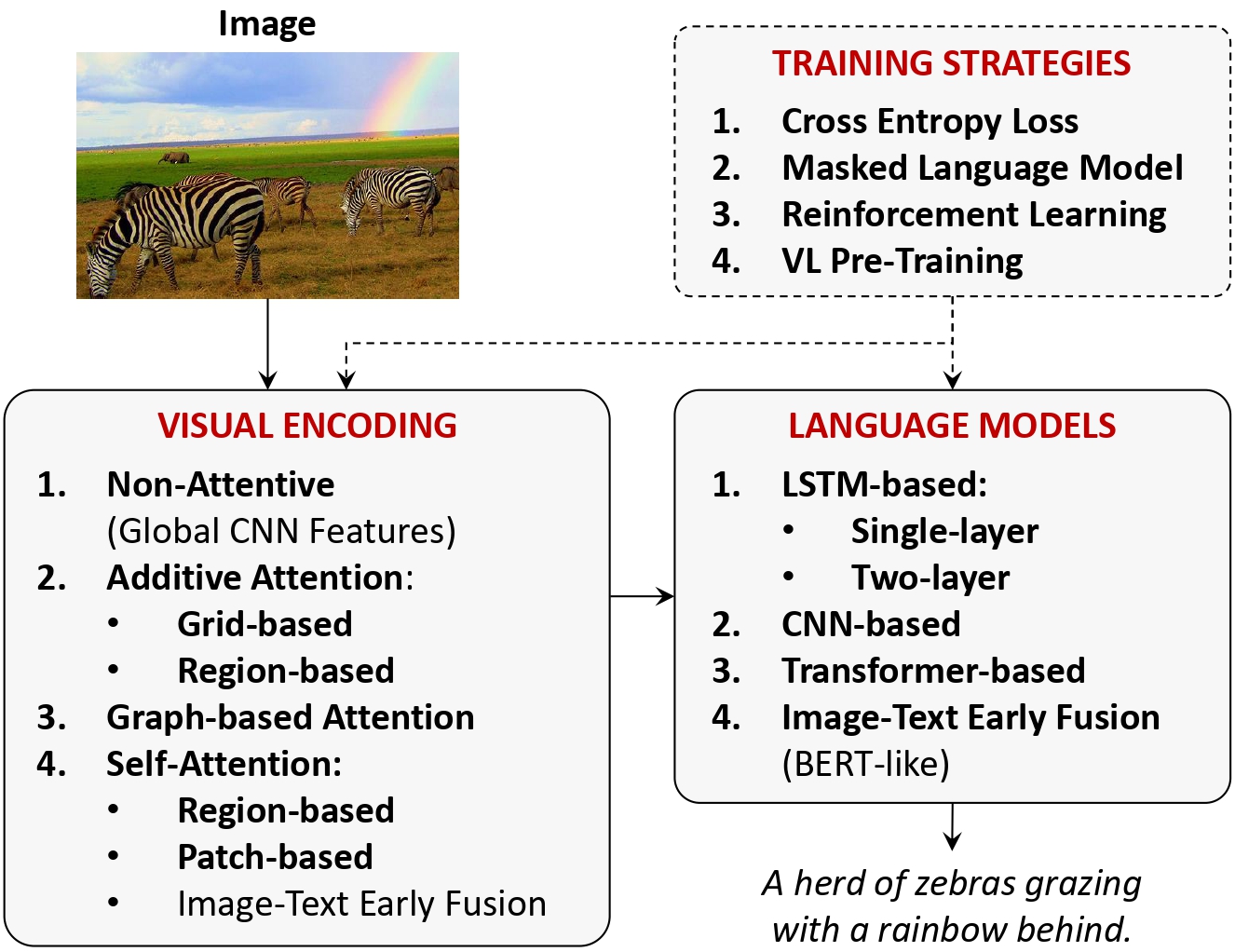
Visual Encoding
Providing an effective representation of the visual content is the first challenge of an image captioning pipeline. Excluding some of the earliest image captioning works, we focus on deep learning based solutions, which have appeared after the introduction of CNNs, and further improved through object detectors and self-attention.
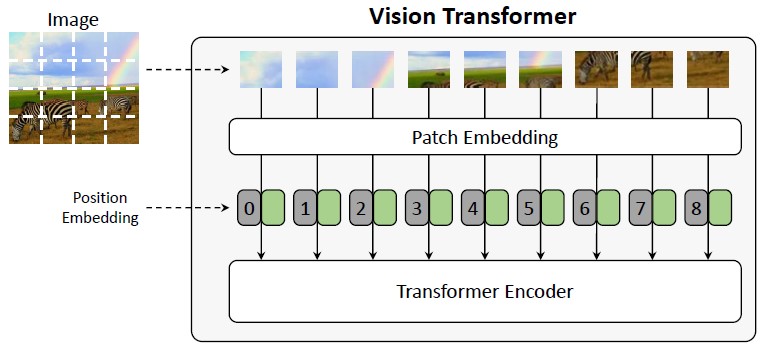
The current approaches of visual encoding can be classified as belonging to four main categories: 1. non-attentive methods based on global CNN features; 2. additive attentive methods which embed the visual content using either grids or regions; 3. graph-based methods adding visual relationships between visual regions; and 4. self-attentive methods which employ Transformer-based paradigms, either by using region-based, patch-based or image-text early fusion solutions.


Language Models
The primary goal of a language model is to predict the probability of a given sequence of words to occur in a sentence. As such, it represents a crucial component of many NLP tasks, as it gives a machine the ability to understand and deal with natural language as a stochastic process.
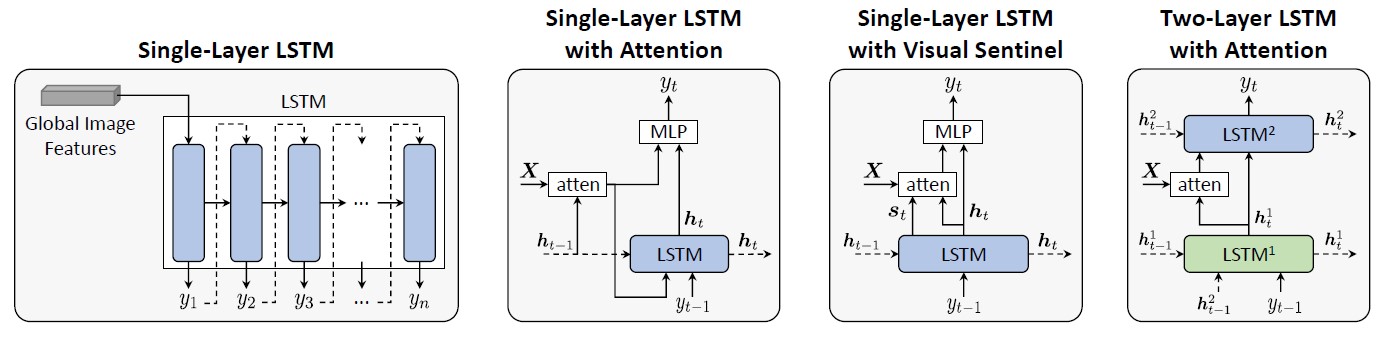
The main language modeling strategies applied to image captioning can be categorized as: 1. LSTM-based approaches, which can be either single-layer or two-layer; 2. CNN-based methods that constitute a first attempt in surpassing the fully recurrent paradigm; 3. Transformer-based fully-attentive approaches; 4. image-text early-fusion (BERT-like) strategies that directly connect the visual and textual inputs.

Performance Analysis
We analyze the performance of some of the main approaches in terms of all the evaluation scores presented in Section to take into account the different aspects of caption quality these express and report their number of parameters to give an idea of the computational complexity and memory occupancy of the models.
The data in the table have been obtained either from the model weights and captions files provided by the original authors or from our best implementation. Given its large use as a benchmark in the field, we consider the generic domain MS COCO dataset also for this analysis. In the table, methods are clustered based on the information included in the visual encoding and ordered by CIDEr score.
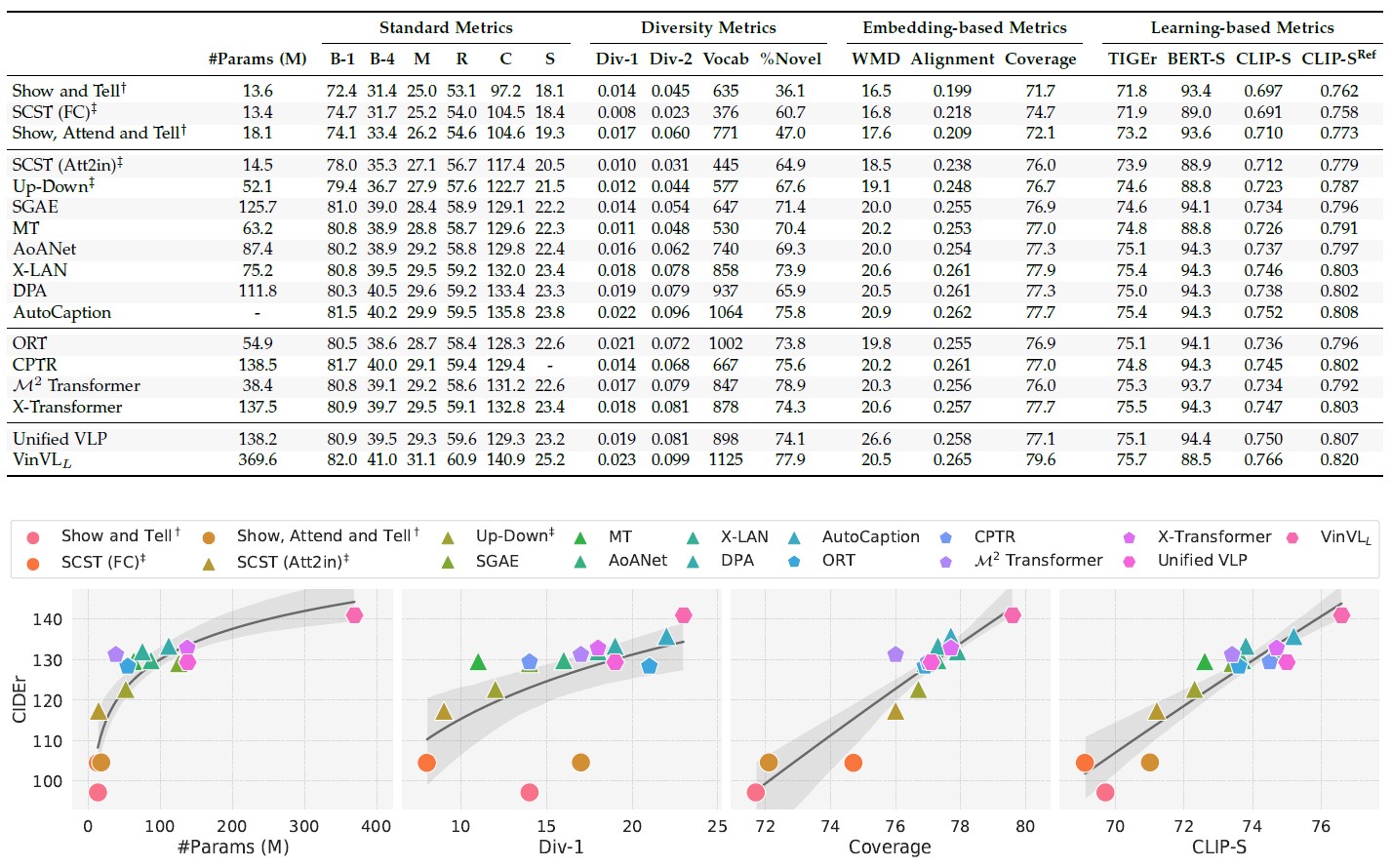
It can be observed that standard and embedding-based metrics all had a substantial improvement with the introduction of region-based visual encodings. Further improvement was due to the integration of information on inter-objects relations, either expressed via graphs or self-attention. Notably, CIDEr, SPICE, and Coverage most reflect the benefit of vision-and-language pre-training.
Moreover, as expected, it emerges that the diversity-based scores are correlated, especially Div-1 and Div-2 and the Vocab Size. The correlation of this family of scores and the others is almost linear, except for early approaches, which perform averagely well in terms of Diversity despite lower values for standard metrics.
From the trend of learning-based scores, it emerges that exploiting models trained on textual data only (BERT-S, reported in the table as its F1-score variant) does not help discriminating among image captioning approaches. On the other hand, considering as reference only the visual information and disregarding the ground-truth captions is possible with the appropriate vision-and-language pre-trained model (consider that CLIP-S and CLIP-S-Ref are linearly correlated). This is a desirable property for an image captioning evaluation score since it allows estimating the performance of a model without relying on reference captions that can be limited in number and somehow subjective.
Qualitative Examples

Acknowledgments
We thank CINECA, the Italian Supercomputing Center, for providing computational resources. This work has been supported by "Fondazione di Modena", by the "Artificial Intelligence for Cultural Heritage (AI4CH)" project, cofunded by the Italian Ministry of Foreign Affairs and International Cooperation, and by the H2020 ICT-48-2020 Human E-AI-NET and ELISE projects. We also want to thank the authors who provided us with the captions and model weights for some of the surveyed approaches.
