

Face Verification with Depth Images
The computer vision community has broadly addressed the face recognition problem in both the RGB and the depth domain.
Traditionally, this problem is categorized into two tasks:
- Face Identification: comparison of an unknown subject’s face with a set of faces (one-to-many)
- Face Verification: comparison of two faces in order to determine whether they belong to the same person or not (one-to-one).
The majority of existing face recognition algorithms is based on the processing of RGB images, while only a minority of methods investigates the use of other image types, like depth maps or thermal images. Recent works employ very deep convolutional networks for the embedding of face images in a d-dimensional hyperspace. Unfortunately, these very deep architectures used for face recognition tasks typically rely upon very large scale datasets which only contain RGB or intensity images, such as Labeled Faces in the Wild (LFW), YouTube Faces Database (YTF) and MS-Celeb-1M.
The main goal of this work is to present a framework, namely JanusNet, that tackles the face verification task analysing depth images only.

Result Reproducibility and Paper Comparison
We created two fixed set of image couples, a validation and a test set, in order to allow repeatable and comparable experiment.
Notes:
- The employed dataset is Pandora, from which we obtain 108 sequences (from 1 to 108).
We unroll all the sequences inside each subject's floder (21 subjects * 5 sequences + 1 subject * 3 sequences)
Link to the Pandora dataset
- We split the dataset in subject-independent subsets:
- Validation set: subjects 9, 18, 21, 22
- Test set: subjects 10, 14, 16, 20
- Train set: remaining subjects (1-8, 11-13, 15, 17, 19)
- You can download two different compressed folders, one for the validation part (validation_set) and one for the test part (test_set)
- In each folder, you will find several .txt files, each of these file has been independently created (i.e. each file is different from the others one):
- <...>_0_1_2.txt: test couples from sequences 0, 1, 2
- <...>_3_4.txt: test couples from sequences 3, 4
- <...>_0_1_2_3_4.txt: test couples from sequences 0, 1, 2, 3, 4
- <...>_angles_frontal_<...>: test couples based only on frontal head poses
- <...>_angles_non_frontal_<...>: test couples based only on non-frontal head poses
- <...>_angles_non_frontal_hard_<...>: test couples based only on extreme head poses
- Each .txt file has the following structure:
- First column: the name of the first image of the couple
- Second column: the name of the second image of the couple
- Third column: a binary value, 1 if the images belong to the same person, 0 otherwise
Downloads:
- Validation Set (.zip format)
- Test Set (.zip format)
For further details, please see our paper published in BMVC 2018.
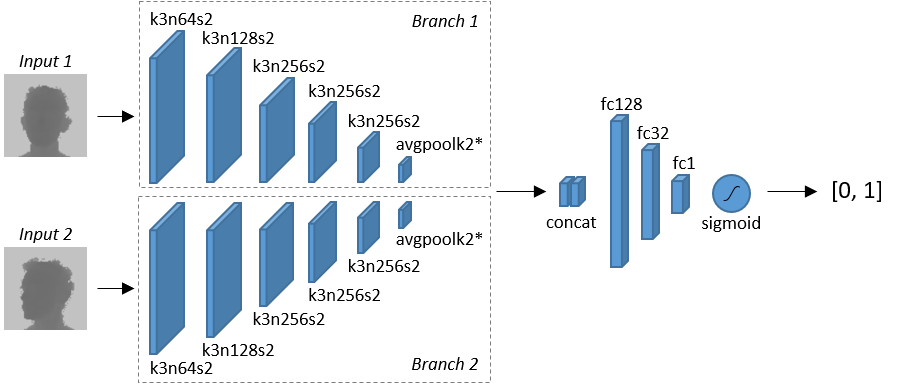
We propose the use of shallow deep architectures is investigated in order to obtain real-time performance and to deal with the small scale of the existing depth-based face datasets, like. In fact, despite the recent introduction of deep-learning oriented depth-based datasets and cheap commercial depth sensors, the usual size of depth datasets is not big enough to train very deep neural models.
Furthermore, we aim to directly detect the identity of a person without strong a-priori hypotheses, like facial landmark or nose tip localization, which could compromise the whole following
We want to exploit Privileged Information to boost the face verification accuracy:
- Training phase: the hybrid Siamese network is conditioned by a specific loss that forces its feature maps to mimic the mid-level features maps of the RGB network;
- Testing phase: the RGB network is not employed, while the depth and the hybrid Siamese network are fed with the same pair of depth images and jointly predict if they belong to the same person.
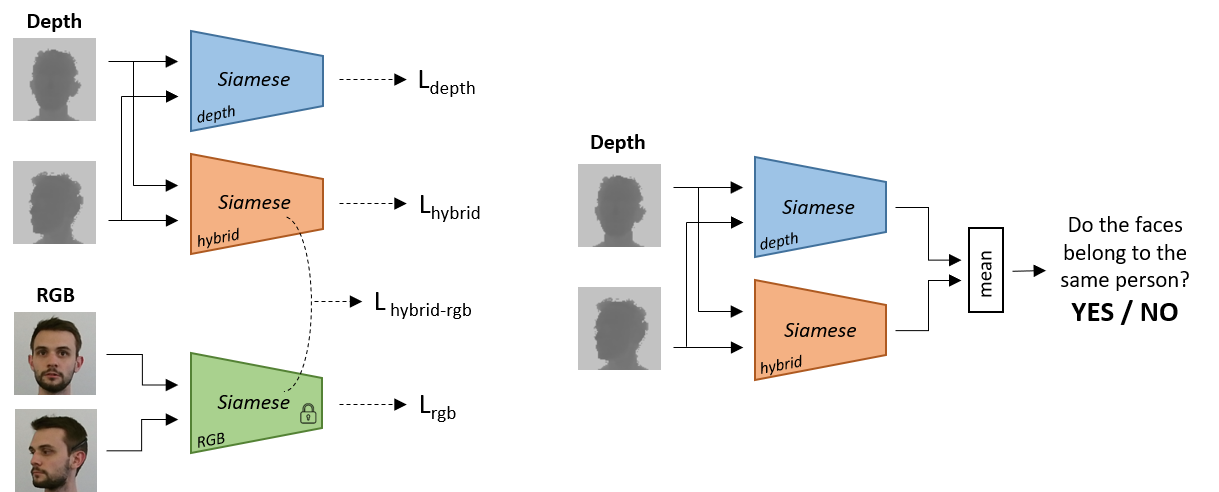
The Siamese networks are meant to predict whether two images belong to the same person or not.
During the training phase, the hybrid Siamese network is conditioned by a specific loss that forces its feature maps to mimic the mid-level features maps of the RGB network.
At testing time, the RGB network is not employed, while the depth and the hybrid Siamese network are fed with the same pair of depth images and jointly predict if they belong to the same person.
Publications
| 1 |
Borghi, Guido; Pini, Stefano; Grazioli, Filippo; Vezzani, Roberto; Cucchiara, Rita
"Face Verification from Depth using Privileged Information"
Proceedings of the 29th British Machine Vision Conference (BMVC),
Northumbria University, gbr,
3-6 September 2018,
2019
Conference

|
| 2 |
Borghi, Guido; Pini, Stefano; Vezzani, Roberto; Cucchiara, Rita
"Driver Face Verification with Depth Maps"
SENSORS,
pp. 19
-3361
,
2019
| DOI: 10.3390/s19153361
Journal
|
